22 minutes
Grafana & InfluxDB pour surveiller un homelab
Dans le cadre de mon homelab, j’ai longtemps réfléchi à mettre en place un monitoring des performances de mon serveur Gath. En partriculier car je peux parfois remarquer certains soucis (ralentissements I/O, le CPU qui souffle, problèmes réseaux), et qu’il est absolument nécessaire de pouvoir conserver un historique de certaines métriques pour comprendre d’où vient le problème :
- utilisation des disques (débit de lecture/d’écriture, et %util, individuellement pour chaque disque/NVMe)
- utilisation du CPU
- températures CPU
- évolution de la charge RAM
- quelques métriques ZFS utiles (taux d’utilisation du L2ARC, taux de remplissage, …)
- la bande passante réseau consommée
- des alertes sur l’espace disque disponible
- idéalement, le nom des processus, ou des binaires, qui siphonnent le CPU, les I/O disques, la RAM, ou le réseau
Toutes ces métriques sont très facilement disponibles au travers d’outils CLI que j’utilise déjà quotidiennement
(htop, btop, glances, iostat, ioztat, zpool status, arc_summary, …). L’enjeu est bien de pouvoir retrouver
des anomalies sur des métriques régulières plutôt que de courrir lancer une commande shell et prier pour regarder au bon
endroit dès qu’il y a un problème de performances.
Solution clé en main sous Home Assistant
(TL;DR : évitez de faire ça chez vous)
Home Assistant est vraiment pratique pour tout mettre au même endroit : des boutons pour allumer ses ampoules connectées, fermer ses volets, démarrer ses VM, voir la météo et les prévisions, …
Il s’oriente intégralement vers un usage domotique : intégration avec tout un tas d’API tierces clé en main pour surveiller et piloter ses appareils, et bac à sable assez simple pour configurer et mettre en place des automatisations.
Ceci dit, la solution se prête davantage à de la mise en forme sobre qu’à du monitoring fin ou avancé :
- le back-end de stockage par défaut n’est pas fait pour sauvegarder, agencer, ou filtrer les données
- Home Assistant supporte l’utilisation d’un back-end InfluxDB pour améliorer significativement les performances sur des installations avec beaucoup de capteurs ou d’entités, ou un historique important, mais ne supporte pas le croisement de données ni les requêtes sur mesure
- la solution de création de dashboards est simple et ergonomique, mais fonctionnellement très limitée à des graphiques de base
- pas de sélecteur simple et global de fenêtre temporelle
- Home Assistant n’est pas conçu dans une optique de monitoring
Pendant deux ans, j’ai testé Home Assistant sur lequel j’ai connecté les intégrations de base de system monitoring et
quelques scripts custom (iostat et arc_summary, pour mes performances ZFS, virsh status pour l’état des machines
virtuelles, pour les principaux). La solution est très rapide à déployer.
Il est utile de préciser que Home Assistant partage une companion app avec des capeurs sur le smartphone. C’est-à-dire qu’au quotidien, c’était assez facile pour moi de surveiller l’état de mon serveur, et de le piloter via les boutons configurés sur Home Assistant (et les commandes qui y étaient reliées).
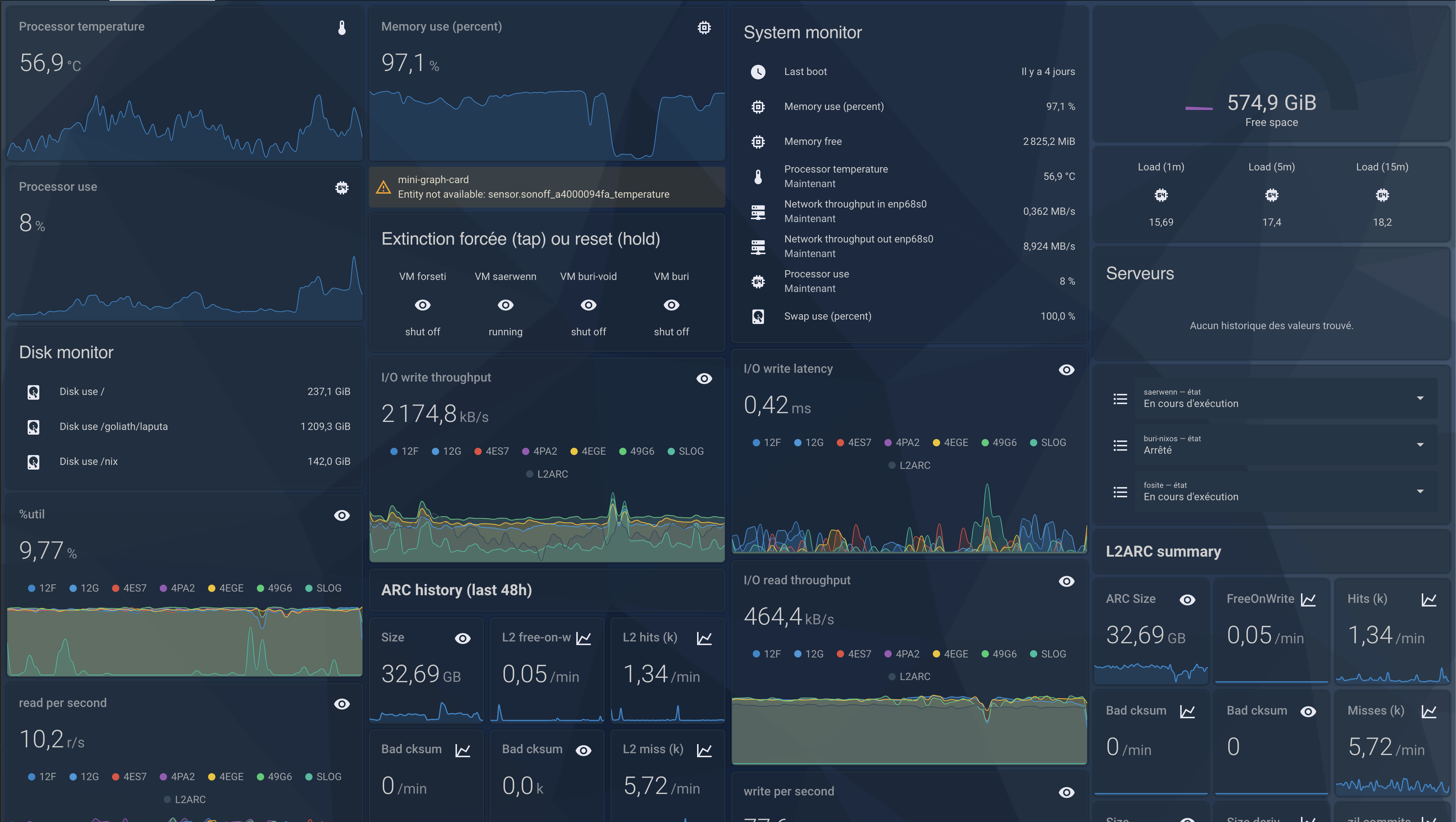
Au quotiden, ça m’a permis de recroiser pas mal d’infos, visuellement, et de définir quelques automatisations :
- j’ai découvert que la température de la pièce baissait de 2°C quand les machines virtuelles avec GPU passthrough étaient coupées
- j’ai pu automatiser l’extinction des VM quand mon smartphone bornait en dehors du domicile (intégration GPS fencing), ou quand le capteur de sommeil du smartphone me jugeait en train de dormir
- j’ai réimplémenté une state machine pour gérer (consulter et modifier) les états libvirt des machines virtuelles via des dropdowns
Ça, et pour l’hiver, je me suis programmé et automatisé un petit chauffage avec du minage de cryptomonnaies pour réchauffer la pièce (histoire de recycler l’électricité en chaleur et en monnaie). J’ai un peu honte d’alimenter le marché des cryptomonnaies, mais certainement pas d’avoir réussi à automatiser une idée aussi stupide :
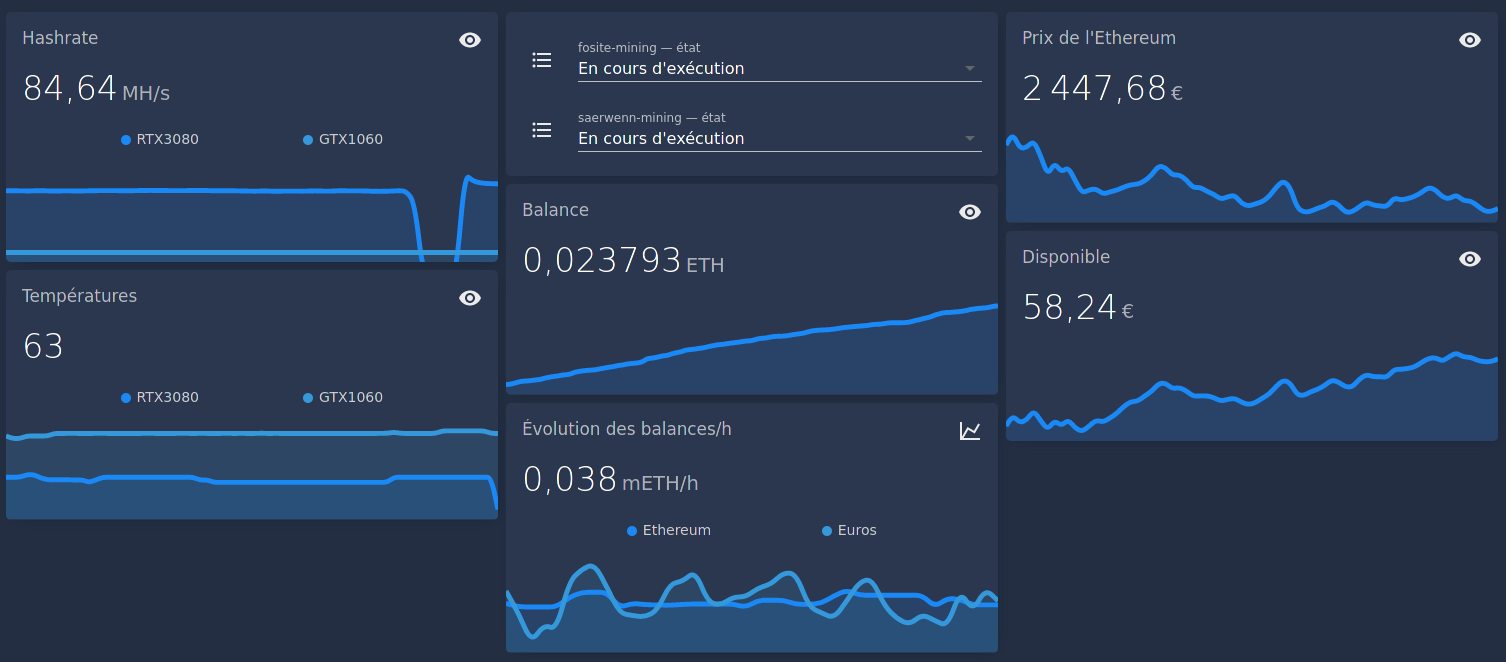
Sur trois mois de mise en œuvre, je crois avoir généré l’équivalent de 50€/mois à l’époque (et je n’ai pas allumé le chauffage), pour des factures d’électricité totales à 70€/mois (je n’ai pas surveillé la consommation électrique individuelle du serveur ; sombre histoire de smartplug dont l’API était inexploitable).
Ceci dit, j’avais besoin d’aller plus loin. Je suis continuellement en train de chercher à optimiser mes I/O, et c’est toujours possible de faire mieux™. Pour ça, j’ai absolument besoin de pouvoir tracker davantage de métriques, d’avoir une granularité plus fine, et de pouvoir recroiser des données.
Le graal ? J’aimerais avoir le niveau d’information d’un htop ou d’un iotop, avec un historique. Et d’être en mesure
de retracer, seconde par seconde, la consommation des ressources I/O disque de chaque processus, afin de pouvoir définir
des limites précises, des priorités d’utilisation disque, ou de corriger un problème à la source.
Dashboards Grafana à la rescousse
Grafana étant un outil de création de dashboards capable de se connecter à pléthore de back-ends/bases de données, j’ai envisagé et testé plusieurs options :
- le connecter à l’instance Home Assistant actuelle pour récupérer les métriques existantes
- envoyer directement les données sur InfluxDB pour les afficher sur Grafana
- passer sur un autre base de données, toujours pour les rendre sur Grafana
À cela, il faut également réfléchir à comment sourcer les données :
- comme originellement, avec un back-end qui exécute les commandes, parse, et enregistre leurs sorties ?
- approche pull-based, à la Prometheus, avec un serveur qui expose les métriques ?
- push-based, où le back-end expose une API vers laquelle on envoie les métriques ?
J’ai tenté deux approches :
- Avec Home Assistant en tant que back-end, pour avoir le moins de changement possible
- Avec une instance InfluxDB (en recyclant la même qu’utilisée par Home Assistant)
Intégration Home Assistant
Assez basique, la solution consiste à configurer Home Assistant pour exposer endpoint au format Prometheus, et y connecter Grafana (tel que suggéré dans la documentation de Grafana).
La solution permettait de conserver tout l’historique des données déjà présentes, mais était handicapante sur les intervalles de rafraîchissement. La fréquence à laquelle Prometheus scrape les données de Home Assistant ne reflète pas forcément la fréquence de rafraîchissement des données (c’est-à-dire que le nombre de points de mesures affichés par Grafana est très probablement différent du nombre réel de points mesurés et disponibles sur Home Assistant).
C’était aussi un peu compliqué de naviguer dans le format de données de Home Assistant, j’aurais aimé pouvoir définir un format plus adapté à la manière de les afficher.
Côté architecture, c’est vite devenu plus complexe que prévu, avec une étape de sérialisation/désérialisation et un intermédiaire supplémentaire :
flowchart LR
Host
HomeAssistant -->|1. Run script | Host
Host -->|2. Return result | HomeAssistant
HomeAssistant -->|3. Expose values | W[Web listener]
Prometheus -->|4. Fetch values | W
Grafana -->|5. Query | Prometheus
Cette solution ajoutait un peu de complexité, tout en rendant le monitoring plus contraignant. On retrouve 5 SPoF : un changement de format, une erreur réseau ou un bug d’un côté de la chaîne peuvent casser toute la chaîne.
Aussi j’ai préféré mieux séparer les responsabilités. Je conserve Home Assistant pour les données de capteurs domotique, et tout le monitoring des systèmes et du homelab est découplé sur une solution à part.
InfluxDB 2
Comme Prometheus, c’est une base de données optimisée sur les séries temporelles. Elle supporte très bien de gros volumes de données y compris sur des machines peu puissantes. Un autre point fort, c’est ça capacité à supporter des données non-structurées avec beaucoup de colonnes et un format qui évolue dans le temps (à l’image d’un ElasticSearch, mais moins usine-à-gaz).
L’intégration Grafana est assez basique, malgré quelques confusions dans les documentations pour les différentes versions d’InfluxDB (qui ne supportent pas les mêmes protocoles API, par exemple). InfluxDB 3 est d’ailleurs sorti (mais très mal documenté/peu intégré, je n’ai pas creusé).
Statistiques système avec Glances
Glances est un genre de htop sur stéroïdes avec tout un tas de plugins pour
surveiller énormément de statistiques. Il peut tourner en tant que daemon, et supporte quantité de protocoles d’export :
pour InfluxDB, mais aussi Cassandra, ElasticSearch, MongoDB, Kafka, en CSV, …
Des changements récents, en alpha, permettent même de monitorer les statistiques par processus, individuellement.
Scripts shell
J’ai encore pas mal de statistiques qui ne sont récupérées que via des commandes shell (comme mes stats d’utilisation
disque par disque, avec iostat, qui exporte en JSON).
Pas d’outil clé en main pour charger une sortie de commande shell dans InfluxDB : j’ai dû mettre en place Telegraf.
Telegraf
C’est un agent de collecte de métriques qui tourne en Go. Beaucoup de connecteurs, c’est un super outil de glue entre des sources de données d’un côté, et des bases de données de l’autre côté.
Ici, j’ai eu besoin de configurer la collecte des métriques sur l’agent, le point de sortie sur InfluxDB, et un point d’entrée de stats :
Configuration Telegraf
Sous NixOS, voici comment j’ai configuré mes buckets & authentification côté InfluxDB (qui peuvent être fait manuellement), Telegraf, et la connexion entre les deux :
1{ pkgs, ... }:
2
3let
4 # Specify the required secret token
5 #influxToken = "";
6in
7{
8 # Monitoring on InfluxDB
9 services.influxdb2.provision.organizations.gath = {
10 buckets.telegraf = {
11 description = "Telegraf bucket, for system monitoring";
12 retention = 63072000; # 2 years
13 };
14 auths.telegraf = {
15 writeBuckets = [ "telegraf" ];
16 tokenFile = pkgs.writeText "token" influxToken;
17 description = "Telegraf reporter write token";
18 };
19 };
20
21 # Telegraf configuration
22 services.telegraf = {
23 enable = true;
24
25 # La configuration qui sera retranscrise en TOML et passée à Telegraf
26 # Cf. https://search.nixos.org/options?channel=23.11&from=0&size=50&sort=relevance&query=services.telegraf.extraConfig
27 extraConfig = {
28 agent = {
29 interval = "10s";
30 round_interval = true;
31 metric_batch_size = 1000;
32 metric_buffer_limit = 10000;
33 collection_jitter = "0s";
34 flush_interval = "10s";
35 flush_jitter = "0s";
36 precision = "";
37 hostname = "gath";
38 omit_hostname = false;
39 };
40
41 outputs.influxdb_v2 = [{
42 urls = [ "http://hass:8086" ];
43 token = influxToken;
44 organization = "gath";
45 bucket = "telegraf";
46 }];
47 };
48 };
49}
Note : la configuration
services.influxdb2.provision
n’est pas tout à fait solide. InfluxDB 2 ne supporte la création de buckets, d’utilisateurs, ou de tokens API que par
mutation, et cette configuration NixOS est simplement traduite en commande Systemd ExecStartPost.
Côté inputs, on a inputs.exec qui nous permet
de récupérer la sortie de iostat via Telegraf pour les stats disques :
1{ pkgs, ... }:
2
3{
4 services.telegraf.extraConfig = {
5 inputs.exec = [{
6 commands = [ "${pkgs.sysstat}/bin/iostat -dxyk 5 1 -o JSON -j ID" ];
7 timeout = "10s";
8 name_override = "iostat";
9 data_format = "json";
10 json_strict = true;
11
12 # To extract the proper fields from `iostat`:
13 json_query = "sysstat.hosts.0.statistics.0.disk";
14 tag_keys = [ "disk_device" ];
15 }];
16 };
17}
On a aussi évidemment des inputs préconfigurées, comme pour les statistiques ZFS par exemple :
1{ pkgs, ... }:
2
3{
4 services.telegraf.extraConfig = {
5 inputs.zfs = {
6 poolMetrics = true;
7 datasetMetrics = true;
8 };
9 };
10}
Et plusieurs centaines d’autres connecteurs qu’on peut retrouver ici.
Visualisation sur Grafana
C’est parti pour tenter de sortir les premiers graphiques sur Grafana.
Dashboards Grafana communautaires
J’ai découvert tout un tas de dashboards publics pré-configurés partagés, pour les sources de données les plus communes. Ils sont disponibles sur le site de Grafana Labs.
Premier essai avec le dashboard communautaire pour Glances :
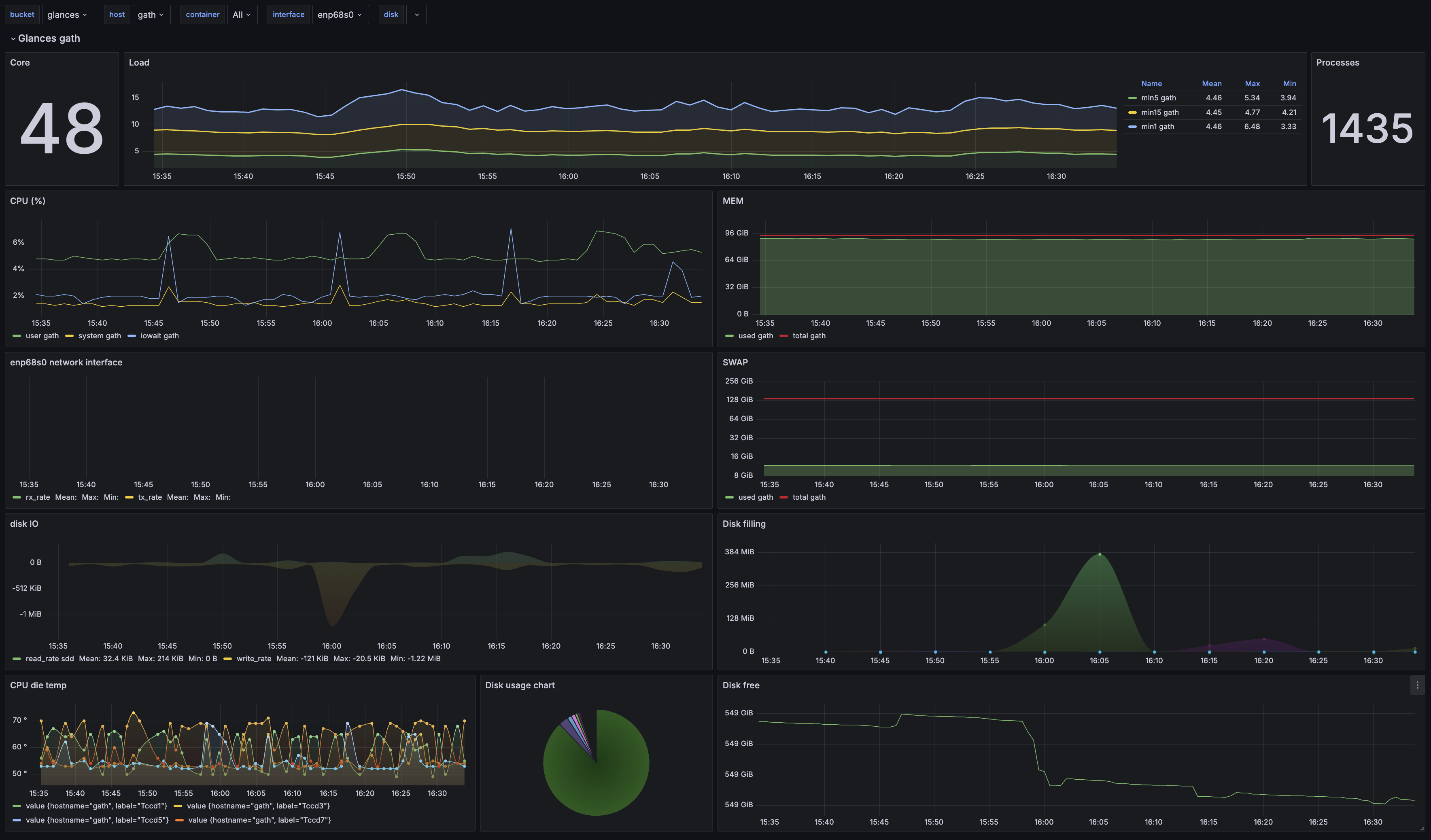
L’installation du dashboard n’est pas tout à fait clé en main. Côté UI Grafana, c’était le plus simple : c’est super rapide de récupérer le dashboard communautaire via son ID, ou en récupérant sa configuration JSON, pour l’importer en deux clics.
Les quelques ajustements qui ont été nécessaires :
- De base, le dashboard Glances ne se connectait pas au bon bucket InfluxDB. J’ai dû chercher/remplacer dans la
configuration JSON du dashboard pour modifier le bucket source (hyper rapide sur Grafana : ⚙️
Settings>JSON Model>Ctrl+F> Déplier le chevron à gauche du champs de saisie pour passer en mode Replace) - Quelques graphs étaient cassés à cause de mauvaises sources, que j’ai rapidement pu corrigen en allant sur InfluxDB, dans le Data Explorer, pour retrouver le format des données et le réajuster dans les graphiques
- Pas de données pour les containers Docker ni pour les capteurs de température. Je n’ai pas vraiment cherché, mais probablement un problème de nomenclature qui a évoluée, et/ou de cardinalité selon les systèmes.
Le seul vrai défaut des dashboards communautaires, c’est que les formats de données évoluent parfois plus vite que les efforts de maintenance de la communauté, rendant plus difficile de trouver des dashboards à jour pour des usages un peu plus niches.
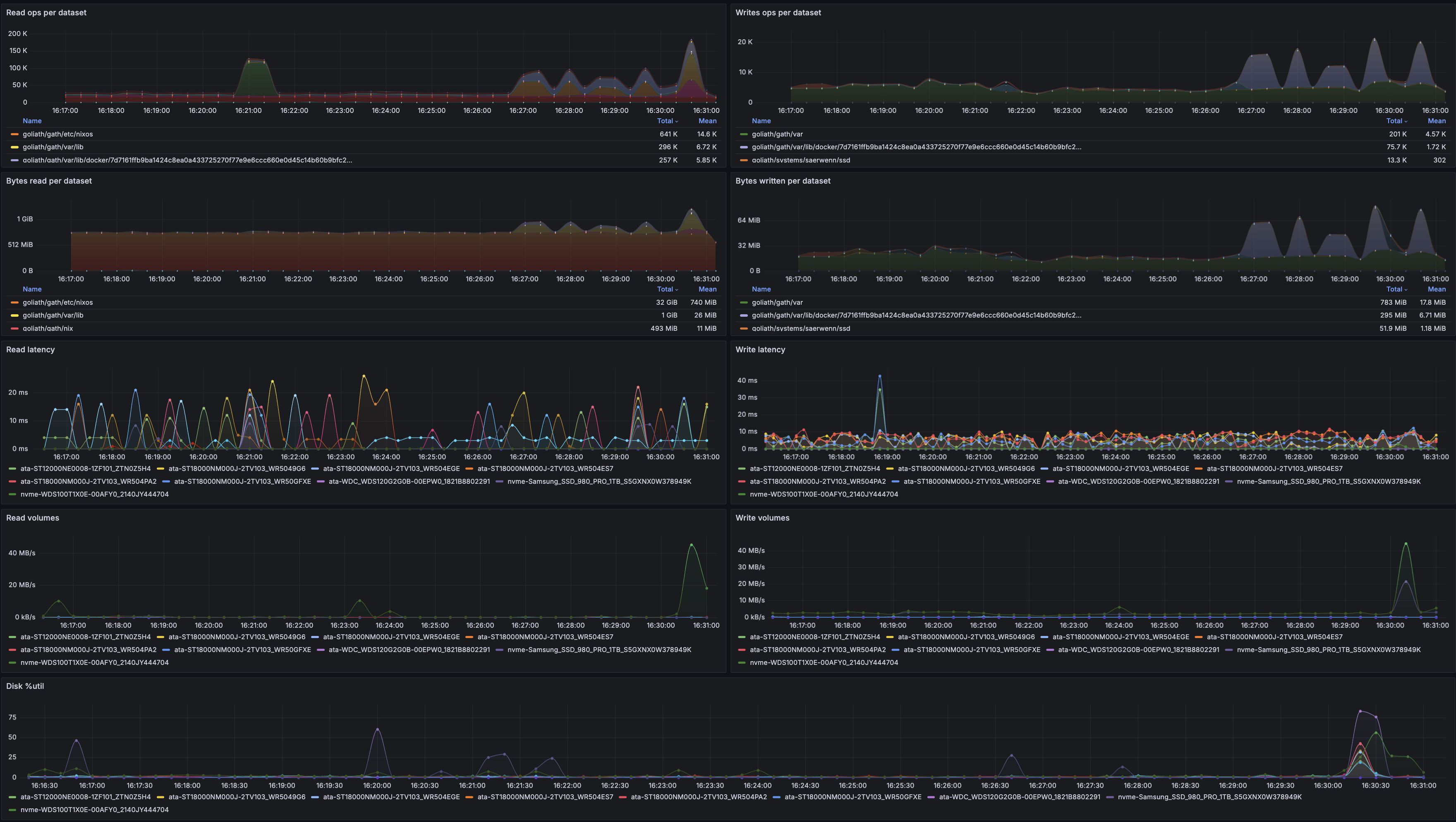
Surveillance des métriques disque
N’ayant rien trouvé d’utile pour les métriques que j’aimerais surveiller, ni côté ZFS, ni côté statistiques disque avancées, j’ai défini quelques métriques à afficher, pour commencer :
- bande passante lecture/écriture par disque et par dataset ZFS
- latence lecture/écriture, par disque
- %util, par disque
- taille des volumes, par dataset ZFS
- nombre de requêtes lecture/écriture, par dataset ZFS
- idéalement, avoir le nom des processus qui consomment en requêtes et en bande passante I/O
Évidemment, tout ça sur des graphiques temporels.
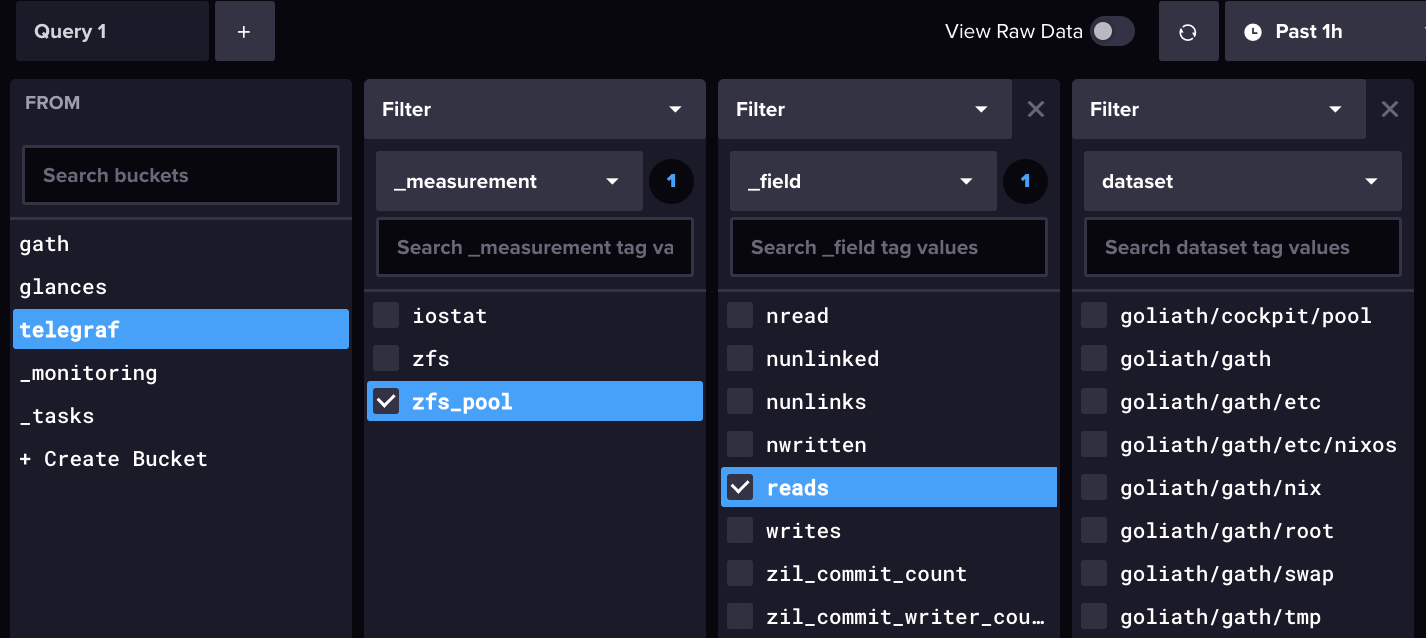
1. Sélectionner une métrique à afficher parmi celles disponibles
Je suis passé par le Data Explorer d’InfluxDB, qui permet d’obtenir très rapidement une liste de champs disponibles.
2. Préparer la requête Flux pour Grafana
De retour côté Grafana, c’est parti pour créer un dashboard ad-hoc pour tenter d’afficher la quantité de lectures par seconde, et idéalement par dataset. On a besoin de récupérer et filtrer les données InfluxDB à partir des champs qui nous intéressent.
Pour ça, lorsqu’on crée une visualisation et qu’on a sélectionné la bonne source de données (“InfluxDB”), Grafana propose des exemples de requêtes disponibles sous le champ de saisie, au travers du bouton “Sample Query”. Ça permet de démarrer rapidement avec les éléments de syntaxe de base.
⚠️ Attention : Les données n’apparaissent dans la visualisation time series que si elles respectent un certain format. Pour consulter les données brutes, Grafana propose l’option “Table view” tout en haut, qui sert beaucoup pour vérifier le format des données. De même, la fenêtre de temps sélectionnée, en haut, peut ne comporter aucune données. Ou bien comporter énormément de données au point de prendre un peu de temps avant d’être exécutée.
:
1from(bucket: "telegraf")
2 |> range(start: v.timeRangeStart, stop: v.timeRangeStop)
3 |> filter(fn: (r) =>
4 r._measurement == "zfs_pool" and
5 r._field == "reads"
6 )
Ce qui donne ceci :
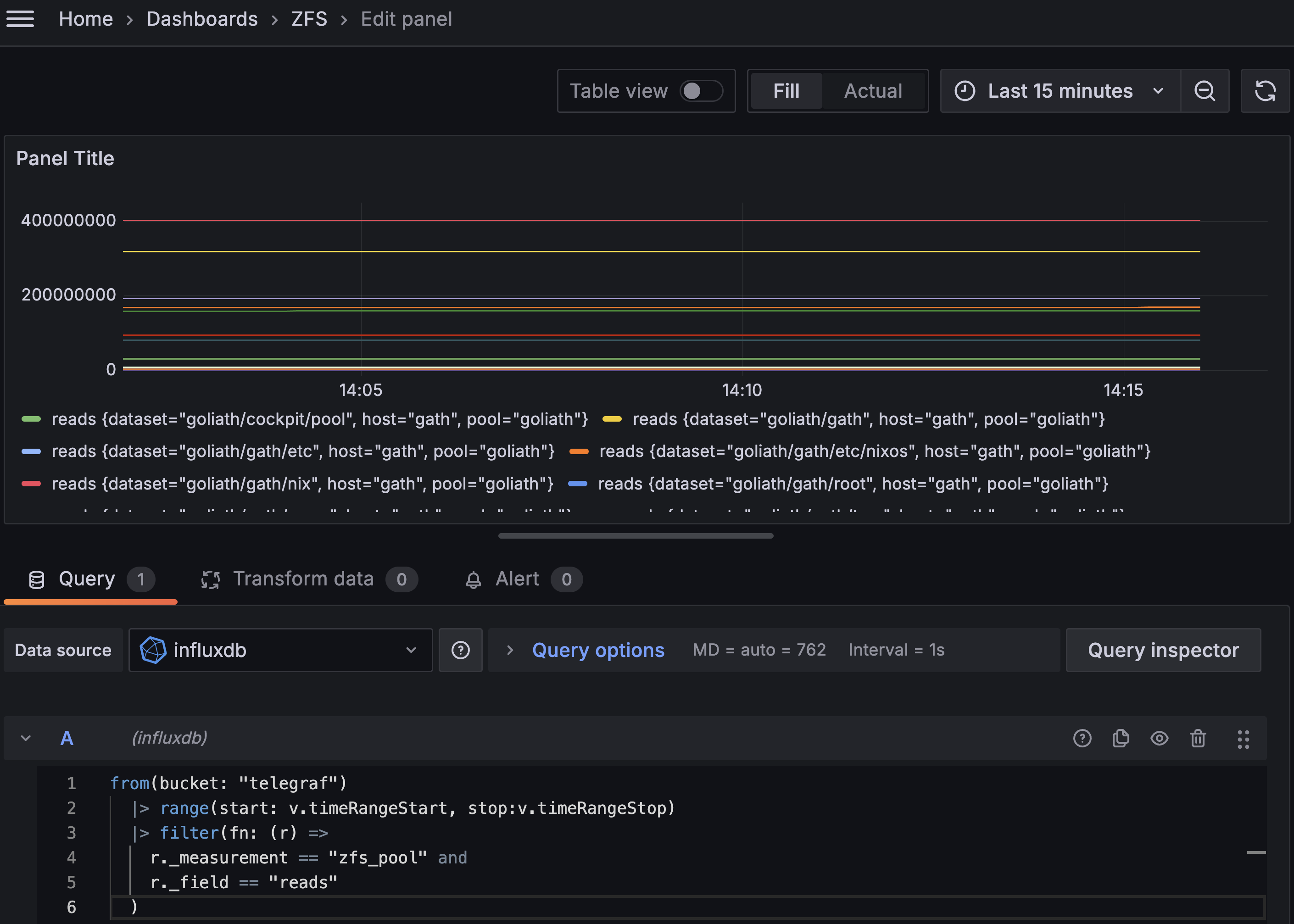
3. Réarranger l’affichage pour faire ressortir les infos intéressantes
On dirait que le compteur de lectures sur le dataset est une quantité depuis le dernier démarrage, et ne s’exprime pas
en lectures par seconde comme je l’espérais. On n’a qu’à calculer une dérivée, ça me semble assez simple avec la
fonction difference() de Flux :
1from(bucket: "telegraf")
2 |> range(start: v.timeRangeStart, stop: v.timeRangeStop)
3 |> filter(fn: (r) =>
4 r._measurement == "zfs_pool" and
5 r._field == "reads"
6 )
7 |> difference()
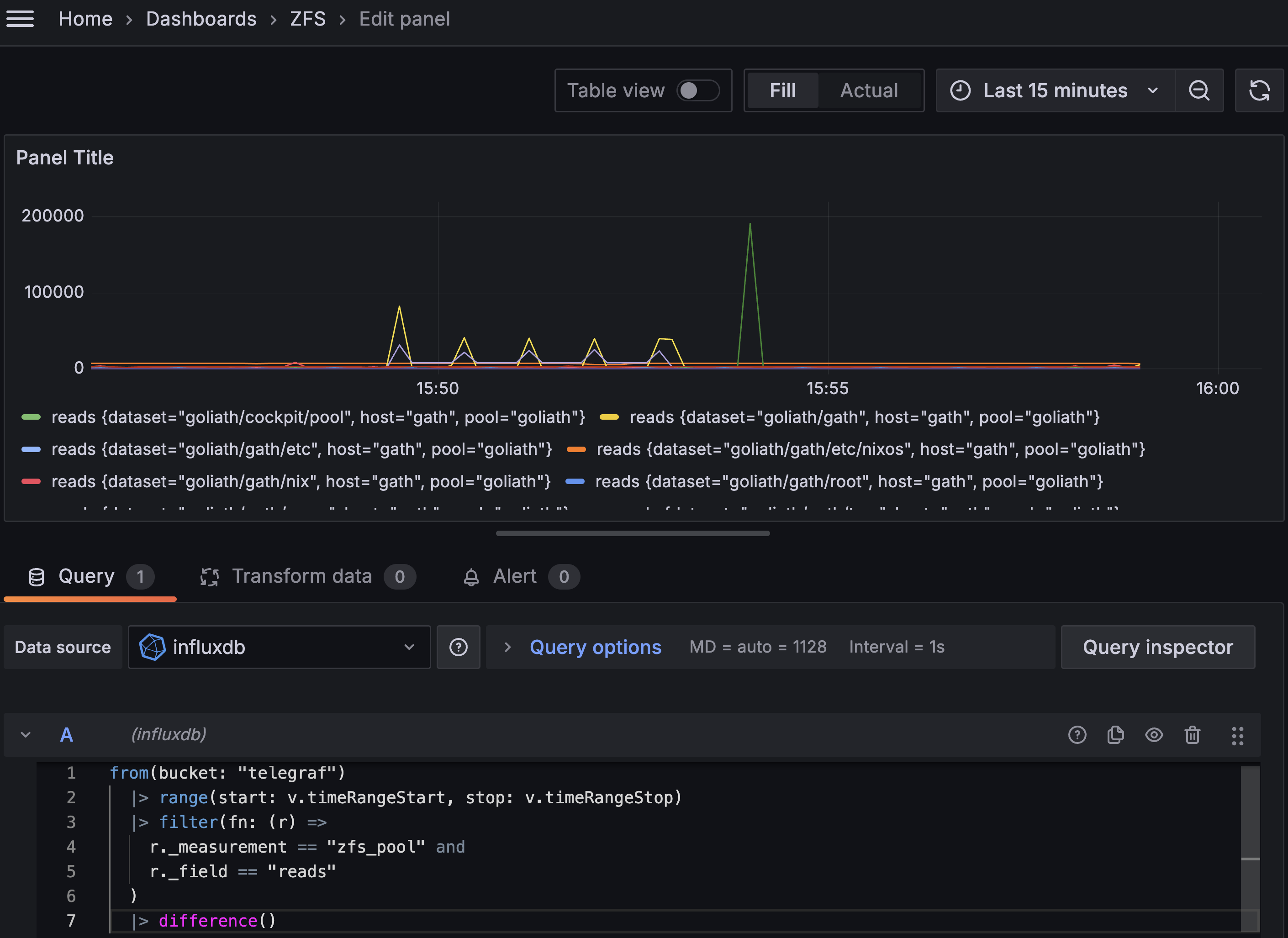
Plus qu’à tenter de rendre ça un peu plus digeste, et un peu plus visuel. Je vois quelques ajustements à faire :
- renommer les courbes pour ne conserver que le nom du dataset concerné (avec
map()) - réduire le nombre de points affichés pour réduire l’échantillonnage pour que ce soit plus lisible (avec
aggregateWindow()) - avoir des courbes un peu plus esthétiques et jolies
La fonction map() permet de remapper certains champs. Ici, il est nécessaire de conserver au minimum trois champs,
pour l’affichage Grafana : _time (pour le timestamp), _value (pour la valeur à afficher sur le graphique), et
_field (pour le nom de la courbe). Les autres champs sont des attributs optionnels qui peuvent être rajoutés dans le
libellé de la courbe (comme dataset, host, pool, sur les captures d’écran plus haut). On n’a qu’à remapper
_field avec la valeur de dataset.
Pour aggregateWindow(), la fonction permet de
réduire l’échantillonnage avec une fonction. Ici, comme on se fiche du nombre exact de read, mais qu’on cherche plutôt
les tendances/les pics, on part sur une moyenne. La période d’échantillonnage peut être définie manuellement, ou via
v.windowPeriod qui est une variable
prédéfinie de dashboarding, générée par Grafana (ou InfluxDB, si on crée le dashboard directement dessus). Comme je ne
voulais qu’une vingtaine de points plutôt qu’une période fixe,
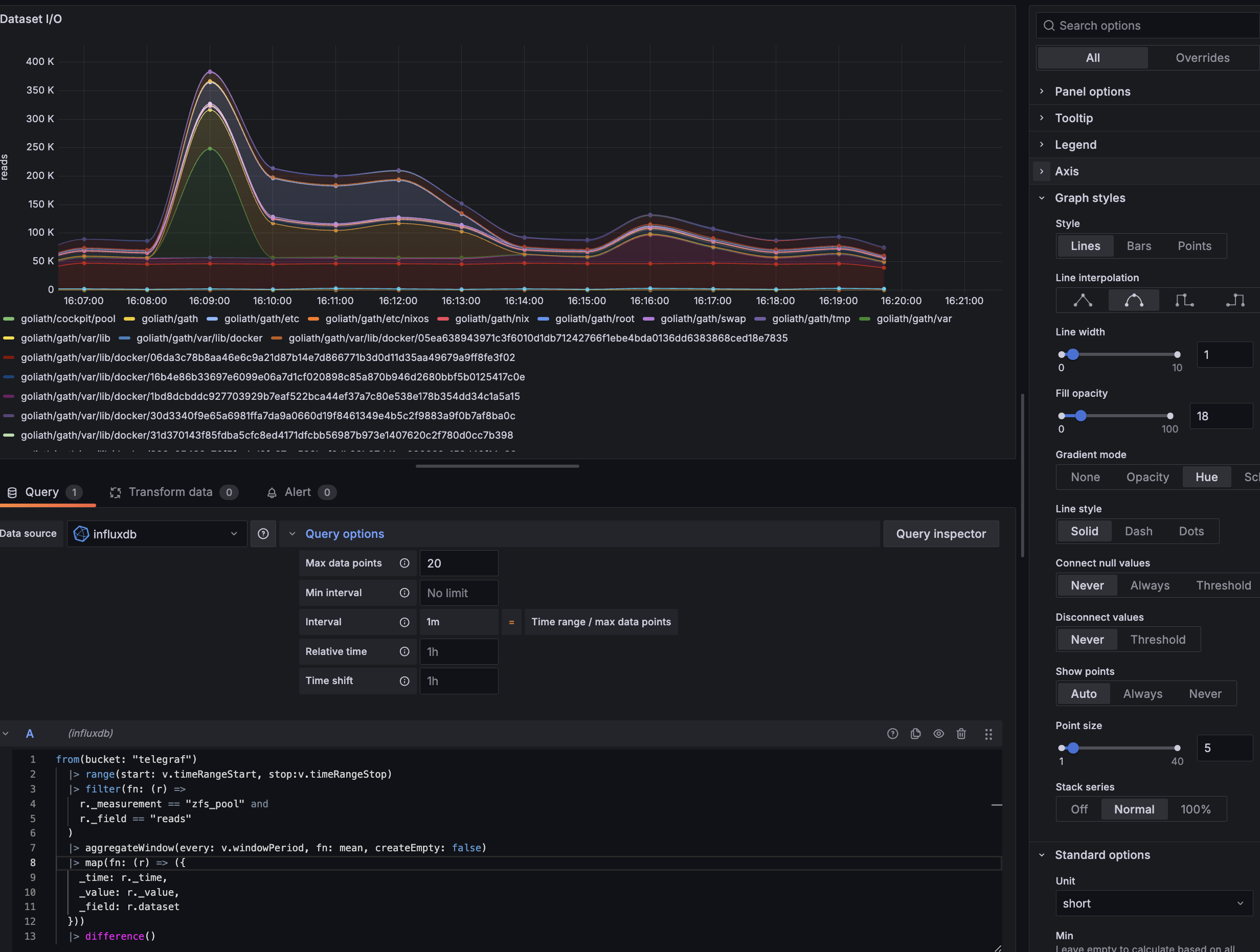
Côté Grafana, j’ai réajusté quelques paramètres :
- le nom du graphique et de l’axe
- le style des courbes, pour avoir des courbes lissées (pas besoin de précision)
- j’ai rajouté une couleur de fond par courbe, pour voir rapidement la couleur des pics
- j’ai passé les courbes en cumulatif avec l’option “Stack series” (car je voulais avoir une estimation du total de lectures sur toute la pool)
Voici ce que donne la requête Flux :
1from(bucket: "telegraf")
2 |> range(start: v.timeRangeStart, stop:v.timeRangeStop)
3 |> filter(fn: (r) =>
4 r._measurement == "zfs_pool" and
5 r._field == "reads"
6 )
7 |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
8 |> map(fn: (r) => ({
9 _time: r._time,
10 _value: r._value,
11 _field: r.dataset
12 }))
13 |> difference()
Et voilà le graphique :
Dashboard final
Chaque graphique m’a pris quinze/vingt minutes à préparer (entre l’écriture des requêtes Flux, la lecture de doc Grafana pour l’affichage, les ajustements de configuration Telegraf pour récupérer les données intéressantes, les tweaks pour réarranger l’affichage, et mes TOC dès qu’il y a un pixel mal placé). Au total, entre la préparation des graphiques, les allers-retours entre le dashboard et le système que je surveillais à la main, et le listing des métriques qui m’intéressaient, j’ai eu besoin de plusieurs heures pour atteindre cette version du dashsboard :
Contraintes et limites
J’ai eu quelques points de douleur sur cette expérimentation. En particulier autour d’InfluxDB :
- la syntaxe Flux n’est pas hyper bien documentée, la navigation dans la doc d’InfluxDB est parfois un peu laborieuse, et on doit souvent naviguer entre plusieurs pages pour comprendre le fonctionnement d’une seule fonction, et les bons paramètres à renseigner ; les forums étant souvent la meilleure source d’information
- la doc InfluxDB mentionne souvent plusieurs langages de requêtes différents, dont le SQL, qui se font concurrence (même si le SQL est déconseillé/obsolète, en faveur de Flux), ce qui rend certaines infos encore plus dures à obtenir
- GPT4 est nul en Flux et hallucine des fonctions et des éléments de syntaxe :D
- j’ai passé plusieurs heures à essayer de faire une jointure entre mes processus Glances et leurs taux d’I/O pour avoir un graphique d’utilisation I/O par processus system, sans succès ; les jointures en Flux n’ont pas l’air mâtures (et la spécification a déjà changé à plusieurs reprises…)
Côté Grafana également :
- parfois un peu difficile de comprendre le format de données attendu pour l’affichage sur Grafana, comme c’est très dépendant de l’intégration
- c’est énormément customizable, donc à la fois on se perd souvent en cherchant les options, à la fois on se perd aussi beaucoup en les trouvant et en essayant toutes les combinaisons possibles
- énormément de choses sont clé-en-main, encore faut-il en connaître l’existence
- comme Grafana supporte énormément d’intégration, c’est difficile de connaître les limites du dashboarding d’un back-end de données sans le tester
En somme, il y a des contraintes techniques et des mises en page impossibles, et difficile à identifier au premier abord. Ça rend toute la solution un peu usine-à-gaz et très orientée tech ; la learning curve est quand même assez pentue, en comparaison à un ELK (hyper intuitif et facile à prendre en main) ou un Datadog (où tout ce qu’on veut faire est déjà dispo en deux clics).
Des logs sous Grafana ?
J’ai aussi pu tester le logging sous Grafana. Rien à redire à ce niveau, c’est l’équivalent de mes souvenirs sur Kibana, en termes d’affichage. En termes d’intuitivité de requête et de setup, je suis peut-être biaisé, mais c’est quand même un petit peu plus complexe.
Pareil ici, j’ai dû déployer une stack complète :
- back-end de logs sous Loki
- agent de collecte de logs sous Promtail
- dashboard sous Grafana
J’ai voulu centraliser la collecte et la consultation de mes logs Systemd sous Grafana (pouvoir recroiser certains logs, faire des recherches, filtrer, …).
Sous NixOS, voici comment j’ai configuré Promtail pour récupérer les logs système :
1{ ... }:
2
3{
4 services.promtail = {
5 enable = true;
6
7 # La configuration qui sera retranscripte en JSON et passée à Promtail
8 # Cf. https://search.nixos.org/options?channel=23.11=0&size=50&sort=relevance&type=packages&query=services.promtail.configuration
9 configuration = {
10 clients = [{ url = "http://hass:3100/loki/api/v1/push"; }];
11
12 scrape_configs = [
13 {
14 job_name = "journal";
15 journal = {
16 max_age = "12h";
17 labels = {
18 job = "systemd-journal";
19 };
20 path = "/var/log/journal";
21 };
22 relabel_configs = [
23 {
24 source_labels = [ "__journal__systemd_unit" ];
25 target_label = "unit";
26 }
27 ];
28 }
29 {
30 job_name = "system";
31 static_configs = [
32 {
33 targets = [ "localhost" ];
34 labels = {
35 job = "varlogs";
36 __path__ = "/tmp/*.log";
37 };
38 }
39 ];
40 }
41 ];
42 };
43 };
44}
J’ai configuré Loki manuellement (sur mon Nuc), et non pas as-code, sous NixOS, puisque je ne voulais pas héberger les solutions de monitoring sur le même serveur que celui à surveiller.
Côté Grafana, une fois l’interconnexion Promtail <-> Loki <-> Grafana faite, plus qu’à tester l’arrivée des logs. Pour ça, lorsqu’on crée une nouvelle visualisation, il suffit de changer le type (par défaut “Time series”) à “Logs” et de sélectionner la source de données (“Loki”).
Côté filtres, comme Loki refuse de sortir un résultat non filtré, il faut spécifier a minima une requête de ce type :
1{service_name=~"systemd-journal"}
Avec quelques ajustements, j’ai créé un dashboard avec :
- une variable pour sélectionner le service à suivre (parmis une liste dont les valeurs sont extraites de Loki, comme proposé immédiatement par Grafana)
- une autre variable pour filtrer les logs sur leur contenu textuel, à partir d’une regex (comme « error », ou « fatal », par exemple)
- un graphique pour voir rapidement les périodes avec des pics de création de logs, en utilisant la fonction
count_over_time()(avec une fenêtre à$__auto)
Pour un résultat final semblable :
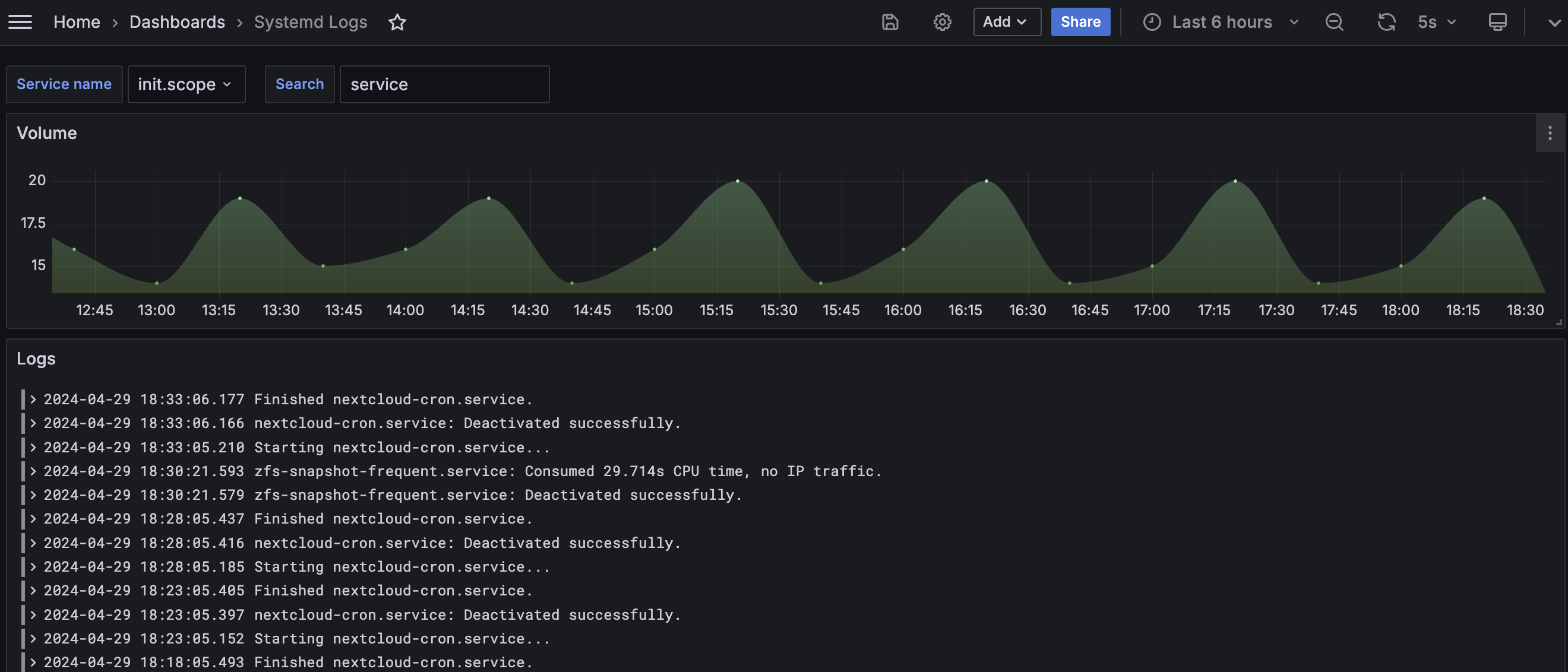
À terme, j’aimerais aussi pouvoir parser automatiquement les lignes de logs pour éliminer les préfixes inutiles/redondants (comme les timestamps…) et avoir une colonne dédiée directement sur le graphique de logs sur Grafana.
TL;DR: conclusions, et la suite
Côté outils
Je ne suis pas vraiment fan du format de sortie de Glances pour son module processlist, en particulier car ça implique
de devoir réaliser des jointures complexes pour associer la consommation mémoire et le libellé du processus. Jointure
qui est franchement galère à gérer de manière efficace côté InfluxDB.
InfluxDB est vraiment bien pour toutes les données dont la structure se prête facilement au requêtage. Les fonctions de mise en forme basiques sont très bien, et les fonctions plus avancées sont rapidement beaucoup moins intuitives, ou limitées par les contraintes techniques de performance d’InfluxDB.
Côté Grafana, j’ai le sentiment que la solution s’adresse à un public technique, tant dans la création de dashboard que dans leur consultation. De mes retours, c’est une solution parfaite quand les personnes qui ont besoin de consulter les dashboards sont les mêmes que celles qui génèrent les données et qui peuvent créer les dashboards, et ne sont pas effrayées par la technicité de l’outil. Au-delà de ces usages, la learning curve est quand même un peu abrupte.
Futurs outils ?
Pour optimiser la consommation de ressources, et définir des limites claires, j’ai absolument besoin d’instrumentaliser correctement les consommations de tous les processus (et de pouvoir déterminer, à n’importe quel moment, quels sont les processus qui ont consommé des ressources I/O disque, par exemple). Chose que je n’ai pas réussie à faire avec InfluxDB depuis Grafana.
J’aurais aimé tenter sa chance avec ElasticSearch comme back-end, tout en conservant le front-end Grafana. ElasticSearch me semble beaucoup plus flexible dans sa manière d’être requêté, et je sais que Glances supporte un export vers ElasticSearch.
Je n’ai pas particulièrement envie de repasser sous Kibana malgré tout, le front-end Grafana étant fiable, et facilement interconnectable avec plein d’autres outils pour tout avoir au même endroit.
Résultats des investigations I/O
J’ai appris pas mal de choses. Notamment le fait que l’un de mes deux NVMe, qui constituent mon mirroir pour mon special vdev ZFS, a une utilisation carrément asymétrique par rapport à son mirroir.
Le NVMe Samsung 980 Pro a une latence de lecture qui grimpe à 8ms fixes pendant des périodes continues, sans explication. À l’inverse, son mirroir, un Western Digital SN550, ne dépasse jamais la milliseconde, et très rarement les 0.3ms. Les deux ont des volumes d’écriture identique (comme ils sont en miroir), mais le WD supporte quasiment toutes les lectures, tandis que le Samsung n’en supporte aucune (probablement car le contrôleur ZFS ne veut pas allouer de lecture à un disque qui a 40× plus de latence que son miroir). Ça crée un goulot d’étranglement sur le WD qui est probablement problématique lors des pics de lectures, faisant exploser la latence, et étant une source probable de freezes.
Je soupçonne le firwmare du Samsung 980 Pro de passer le NVMe en « basse consommation » pour économiser des ressources physiques lorsqu’il est peu sollicité (une sorte de mode veille). Je retrouve ce comportement lors de benchmarks de lecture sur le NVMe : la latence est à 8ms au démarrage du benchmark, avant de redescendre sous les 0.3ms au bout d’une dizaine de secondes. La vraie problématique, c’est qu’il est en miroir avec un disque qui n’a pas ce comportement (malgré des performances théoriques et benchmarkées très proches), et que le contrôleur ZFS semble prioriser le périphérique le plus rapide pour les I/O, gardant, de fait, le NVMe Samsung froid et en veille.
Côté logiciel, j’ai découvert que certains services consomment quantité démesurées de ressources disque, par exemple pour des scans réguliers et inutile lancés chaque minute de certains de leurs volumes, pour vérifier des changements (je pense à la suite Sonarr/Radarr/Lidarr). À tel point qu’ils saturaient les I/O de leurs volumes 100% du temps (tâches récurrentes lancées chaque minute, qui duraient jusqu’à 10 minutes chacune).
Plus qu’à remonter les logs, continuer de surveiller les comportements, et tenter de les limiter techniquement
(cgroups ?) au cas par cas !
4543 Mots
2024-04-29 16:00